
What is the Data Lakehouse and should I care?
This post from October 2022 is a write up of the Databricks “Data and AI” world tour in London.



Before the Lakehouse
Back in 2018 we trialed using Databricks for Data Science at the Co-op. I gave a presentation at the Spark+AI Summit (supported by Databricks) conference in London. The conference was (obviously) really focussed on the Spark data engine and its use for AI.
The results of the trials were impressive, and we were going to continue to use Databricks for our most difficult problems. However, there were some features of using the system that meant that we weren’t going to use it more widely:
- You had to load your data into a different “thing” from your usual database (Databricks files), which needed data engineers to move data around for the analysts;
- It took time to start a work session, compared with the simplicity and speed of opening a query window and getting going;
- The whole thing felt a bit disassociated from the rest of our work in Azure, where we were curating data, documenting metadata and building dashboards and visualisation in PowerBI.
In short, it was a great data science tool for the biggest tasks and part of the capabilities that we needed, but was never going to be used for everything. Our analysts spend most of their time in SQL query windows and only used Databricks for specific projects. What we needed was to have a more integrated platform where the data science tools and data coexisted with the analysis tools and business reporting data. We need a Lake and a Warehouse!
Data Lakehouse – the theory
Databricks have been talking about the architectural pattern called “data lakehouse” for some years. To begin with, it felt like a bit of “sales architecture” – a story to tell people so that they get what you are trying to sell and where it fits in the general scheme of things. The Data Lakehouse was a “paradigm” that combined the best parts of the Data Lake (flexibility and speed) with the best parts of the Data Warehouse (robustness and delivery of information to the organisation).
This “Dummies” book on the Databricks website is a quick read and explains the above concepts really well. This book was released in 2020, along with a few other articles on the Databricks website.
As a paradigm, the Data Lakehouse certainly makes sense. Anyone with a “Lake” or “Warehouse” only architecture will be struggling to get the full potential value from their data. Unfortunately, having both a Lake and a Warehouse meant twice as much work. We had to load the Data Lake first and then load some data from there into the Data Warehouse. Or we had to develop Lambda architectures to load different types of real-time data twice into our systems. Or we have to work out how to give Data Scientists access to both the business focussed “gold” data along with the more atonic “silver” data.
(Databricks use a “medallion” pattern to logically describe and separate the different levels of data processing in the warehouse. It’s a simple way to explain the age-old process of processing raw data into something that the analysts use.)
A key part of the Data Lakehouse paradigm / pattern is that it fulfils the use cases of the Data Lake and Data Warehouse in one system. This silver bullet of an architecture sounds ideal. What Databricks are saying now is that they now have the technology to make that architectural pattern a platform reality.
Data Lakehouse – the platform
At last week’s “Destination Lakehouse” event in London, Databricks presented how the Lakehouse is now possible with the maturing of technology. I’ll give an overview here, but I recommend further reading on the Databricks website.
Delta Lake
Delta Lake is a key technology that enables this to work. It is the workhorse of the platform. Delta Lake 2.0 was released in the summer and is one of those massive open-source technologies that is supported by Databricks. It basically solves the problem of how to run the features that we would expect to have in a Data Warehouse system in the Data Lake.
The core of Delta Lake is that it offers data management capabilities on files stored in the Data Lake (see the picture below and click the picture to get more details). That means that we can now build the Data Warehouse in files that are stored in the Lake and we’ve got just one seamless system to manage.
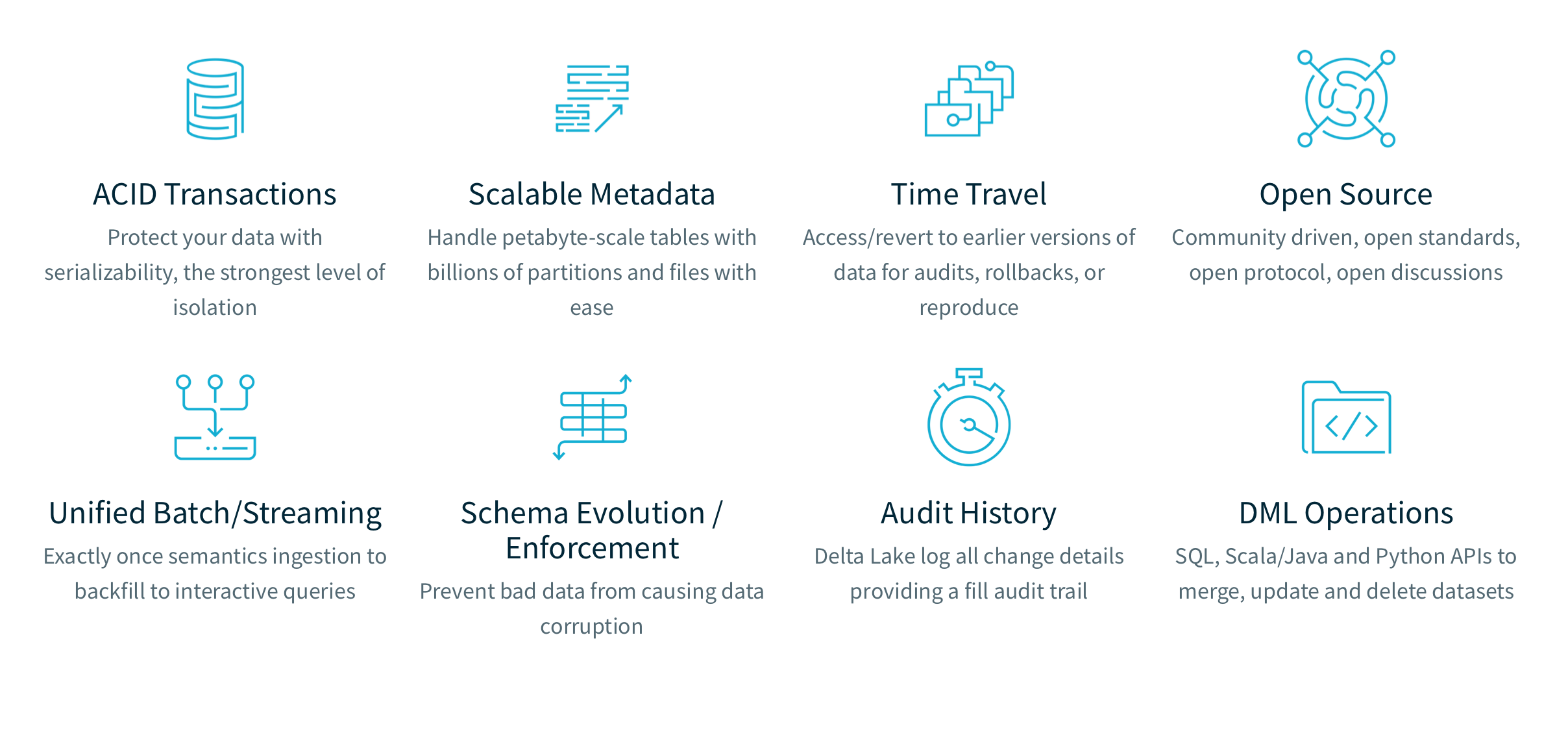
The cost / query performance of Delta Lake is such that it now rivals or beats many of the more established technologies. So building your data warehouse in Delta Lake isn’t a compromise, it’s now a real option to be considered.
Unity Catalog
Another component of Databricks’ view of “what you need in a Data Lakehouse” is “Unity Catalog”. Unity Catalog is YAAC (Yet Another Automated Catalog). OK, that’s mean, but why would this one get traction? Well, firstly, it’s closely integrated with the rest of the Data Lakehouse platform. That means a lot of metadata and lineage “come for free”. Having lineage built from the pipelines (see Delta Live Tables below) means that it will always be up-to-date (compared with those wikis that are so nearly right).
Secondly, it is also the place to manage your security and permissions. Too many providers separate governance of access from governance of definitions, and having them in the same place creates more of a reason for users to use that technology.
Finally, Unity Catalog is also open and has adaptors and integrations to some of the more popular proprietary catalog tools. Databricks are serious about cataloging and governance and have recently announced an investment in Alation.
Delta Live Tables
This is another bit of technology with a name that belies its importance. Basically, the “live” bit of the tables is that they are automatically generated by pipelines. So you write a bit of SQL that describes that the table is “all the source table with this selection and just these columns”. So far, so simple and not mind-blowing.
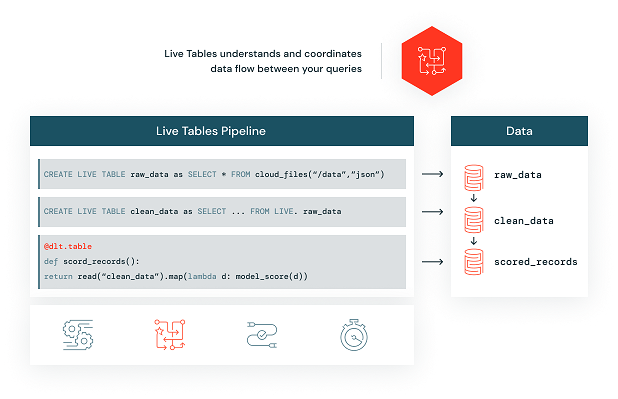
You also crucially get these great features:
- you can choose to build each subsequent run of the query as a complete refresh or as incremental builds,
- you can build data quality checks into the query as “expectations” and therefore alter, drop or fail the rows or query,
- it becomes part of Unity Catalog’s lineage, and
- it maintains run stats in the pipeline orchestration system.
Yes, it’s a complete data warehouse loading framework. The important stuff (the actual business logic) is user written, but all the rest of it comes for free. Obviously, there are other tools that do this, and some of those are available as integration points, but the integration and simplicity of this will change the way dataops works in many businesses.
Should I care as a data leader?
Of course, you should care about such a key development by a major player in data technology. Now that you care, what are you going to do about it? The answer to that question is very dependent on your situation. Here are some prompts:
”I don’t really know much about Databricks or other technologies like Snowflake, dbt, Fivetran or Alation” – it’s really time that you made sure that you and your team understand what these technologies are. You might be tied into your current technology choices, but you should be thinking about what these vendors are telling us about the future of data platforms.
”My data strategy was written two years ago and doesn’t say much about new technology” – it’s really time to dust off at that strategy. Every strategy should be refreshed ideally every year, but certainly every two years. Given the number of changes in the world recently, you should be revisiting some of your choices around technology, talent and sourcing are checking that your previous assumptions are still valid.
”I’m tied into my current system and won’t be changing for two years” – now is definitely the time to start researching and firming up your plans. It’s not possible to change quickly, and therefore you should at least spend some time now thinking about whether you need to change and how can you make that migration easier.
”This is brand new and I am not convinced that we are a cutting-edge type of place” - That’s OK, if that is a conscious choice that is part of your data strategy. Make sure that your stakeholders know that you have a position on this type of technology and architecture.
”My strategy and delivery partners don’t say much about this” – get new partners! Any good partner will have a viewpoint on this and should be able to explain why they aren’t talking to you about the latest trends and technologies.